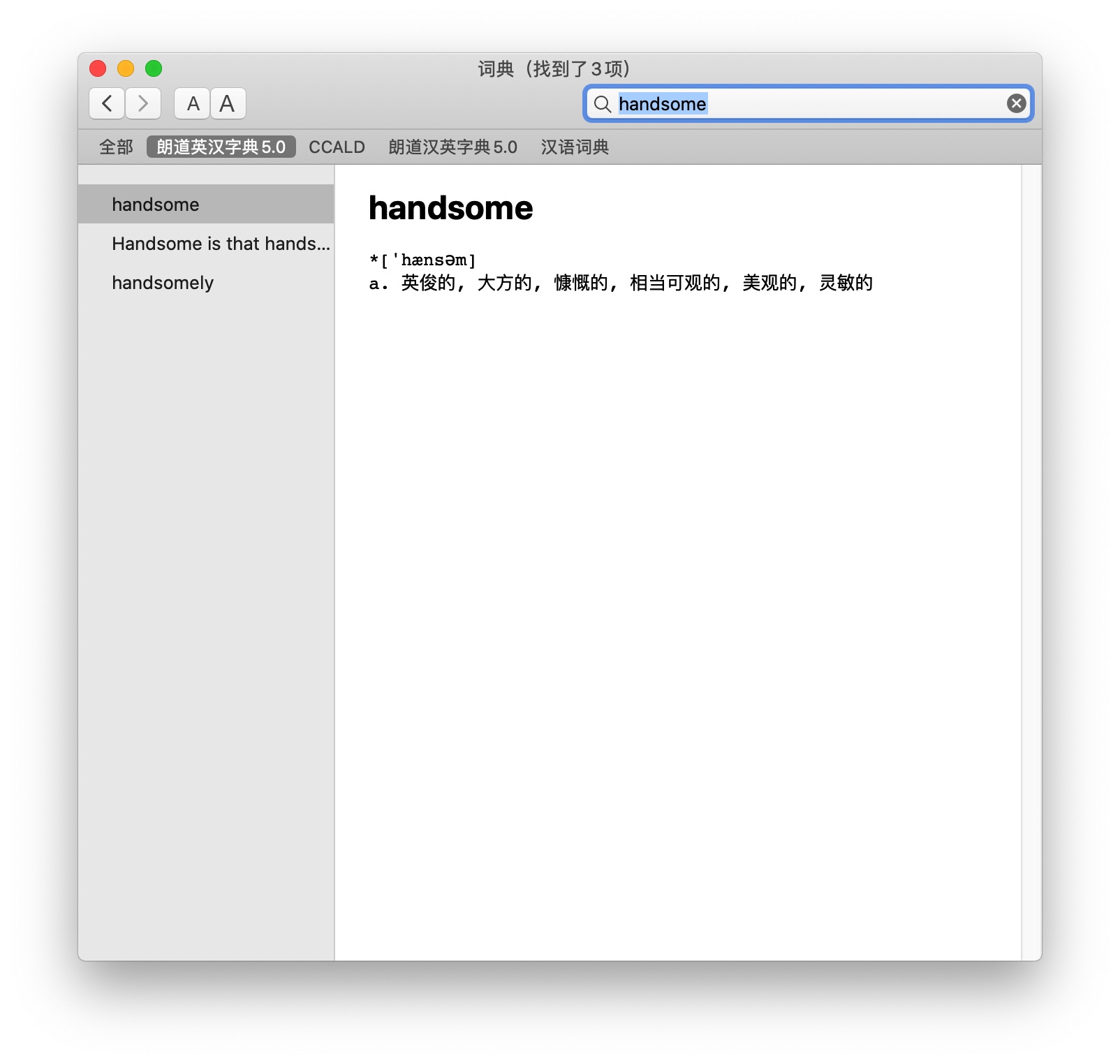
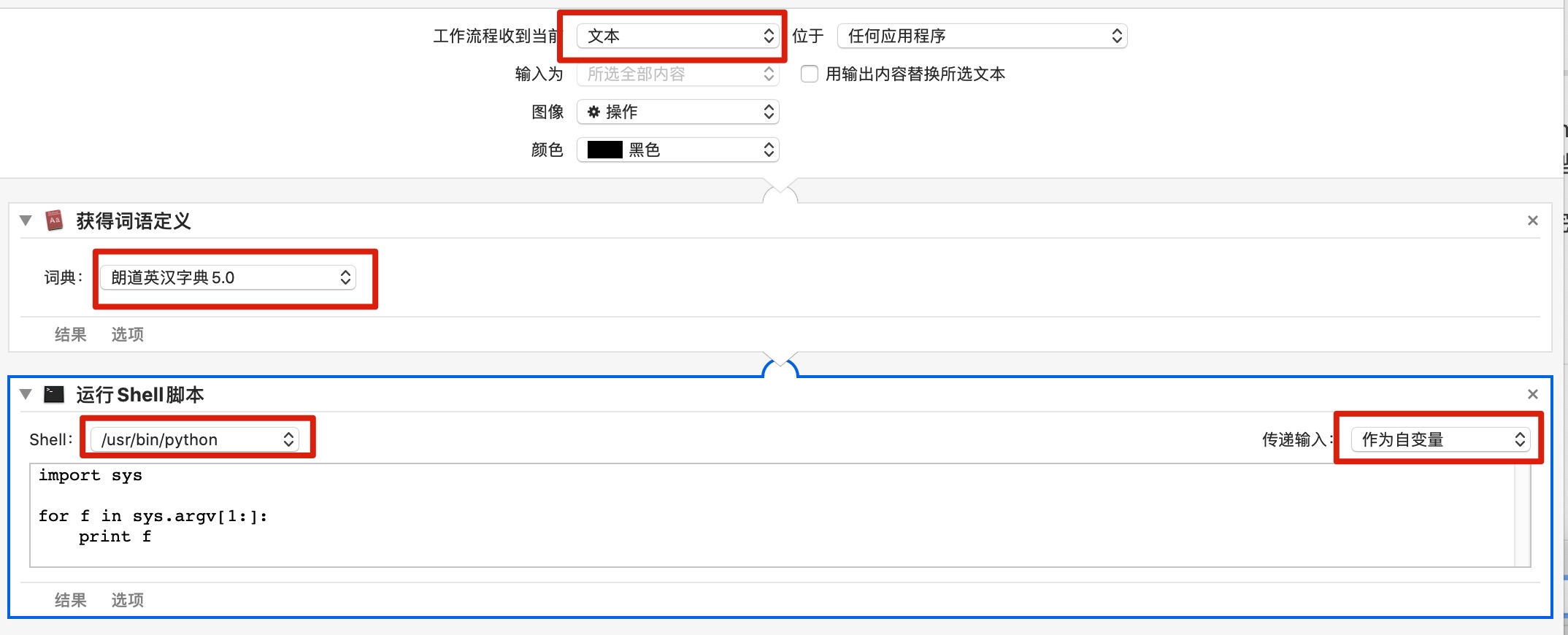
from __future__ import unicode_literals, print_function import sys, os, io, subprocess
FILE=os.path.expanduser("~/weiyun_sync/!sync/logseq-note/pages/生词本.md") output = [] text = sys.argv[1].decode('utf8') if sys.version_info.major == 2else sys.argv[1]
lines = [i.strip() for i in text.splitlines() if i.strip()] if len(lines) < 2: exit(0)
word = lines[0] if lines[1][0] == '*': output.append('- {}\t{} [[card]]'.format(word, lines[1])) lines = lines[2:] else: output.append('- {}\t [[card]]'.format(word)) lines = lines[1:] output.append('\t- {}'.format(lines[0])) for line in lines[1:]: output.append('\t ' + line)
old_words = set() with io.open(FILE, 'r', encoding='utf8') as fp: for line in fp: parts = line.split() if line.startswith('-') and len(parts) > 1: old_words.add(parts[1])
if word notin old_words: with io.open(FILE, 'a', encoding='utf8') as fp: fp.write('\n') fp.write('\n'.join(output)) fp.write('\n') subprocess.check_call(['osascript', '-e', u'display notification "添加 {}" with title "生词本"'.format(word)]) else: subprocess.check_call(['osascript', '-e', u'display notification "跳过 {}" with title "生词本"'.format(word)])
a:3 3 3 3 b:3 <function main2.<locals>.<lambda> at 0x10ca30310> <function main2.<locals>.<lambda> at 0x10ca30310> <function main2.<locals>.<lambda> at 0x10ca303a0> <function main2.<locals>.<lambda> at 0x10ca303a0> <function main2.<locals>.<lambda> at 0x10ca30430> <function main2.<locals>.<lambda> at 0x10ca30430> c:<function main2.<locals>.<lambda> at 0x10ca30310> <function main2.<locals>.<lambda> at 0x10ca30430> 4 5 6 d:<function main2.<locals>.<lambda> at 0x10ca30310> 6
#test if test 1 -eq 2 || test 1 -eq 1; then echo True fi
# [ ] if [ 1 -eq 2 ] || [ 1 -eq 1 ]; then echo True fi
# [[ ]] if [[ 1 -eq 2 || 1 -eq 1 ]]; then echo True fi
逻辑操作符
判断条件支持且(&&)或(||)非(!)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# not if [[ ! 'aa' == 'bb' ]]; then echo True fi
# or if [[ 1 -eq 2 || 1 -eq 1 ]]; then echo True fi
# and if [[ 1 -ne 2 && 1 -eq 1 ]]; then echo True fi
判断时引号使用(quote)
使用[和test时,变量引用注意加双引号,否则得不到正确的结果,[[则不需要。
1 2 3 4 5 6 7 8
bash-3.2$ echo "$SSH_CLIENT"
bash-3.2$ if [ -n $SSH_CLIENT ]; then echo 1; else echo 0; fi 1 bash-3.2$ if [ -n "$SSH_CLIENT" ]; then echo 1; else echo 0; fi 0 bash-3.2$ if [[ -n $SSH_CLIENT ]]; then echo 1; else echo 0; fi 0
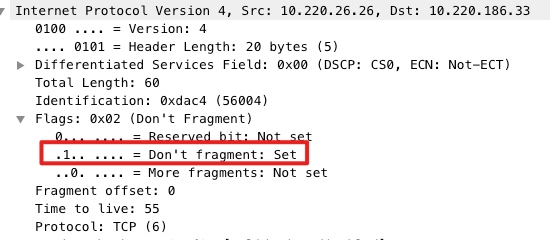
按我的知识,docker0是网桥,等价于交换机,除了性能问题,不应该导致丢包,就一直没往这个方向考虑(当然这块的知识也不扎实)。 MTU也不应该导致丢包,交换机应该会进行IP分片。 但忽略了一个点,虚拟的网桥并不是硬件网桥,可能并没有实现IP分片的逻辑(仅丢弃),又或者没有实现 PMTU(Path MTU Discovery)。 上面这点存疑,但更直接的原因是服务的IP包的 Don't fragment flag 为1,也就是禁止分片(为什么设置还不清楚)。
BASE=/srv/nfs_root TODAY=$(date +'%Y%m%d') USERS=( data ) # read -r -a USERS <<< $(groupmems -g users -l)
cd$BASE for share in $(ls); do for user in${USERS[@]}; do rec="$BASE/${share}/.recycle/$user" if [[ ! -d $rec ]]; then mkdir -p $rec fi cd$rec if [[ ! -d $TODAY ]]; then mkdir $TODAY fi if [[ -L today || -f today ]]; then rm -f today elif [[ -d today ]]; then mv today $TODAY/$(date +'bak.%s') fi ln -s ./$TODAY today done done
windows 系统中,增加定时任务,删除NFS共享目录中的回收站文件到系统回收站 Python 代码如下,超过一定时间的文件会被送到 windows 回收站
defget_size(path: str) -> int: return sum(p.stat().st_size for p in Path(path).rglob('*'))
defmain(): exports = [] for line in open(EXPORTS_FILE): parts = line.strip().split() ifnot parts or parts[0].startswith('#'): continue exports.append(parts[0])
dt = (datetime.now() - timedelta(days=KEEP_DAYS)).strftime('%Y%m%d') for export in exports: for user in USERS: rec = os.path.join(export, '.recycle', user) if os.path.exists(rec): for item in os.listdir(rec): path = os.path.join(rec, item) # print(path, get_size(path)) if os.path.isdir(path) and item.startswith('2') and item < dt: size = get_size(path) if size <= 0: logging.info('rm empyt\t%s', path) os.rmdir(path) else: logging.info('trash\t%s', path) send2trash(path)
if __name__ == '__main__': whileTrue: try: logging.info('check') main() time.sleep(3600) except Exception as e: logging.exception(e)
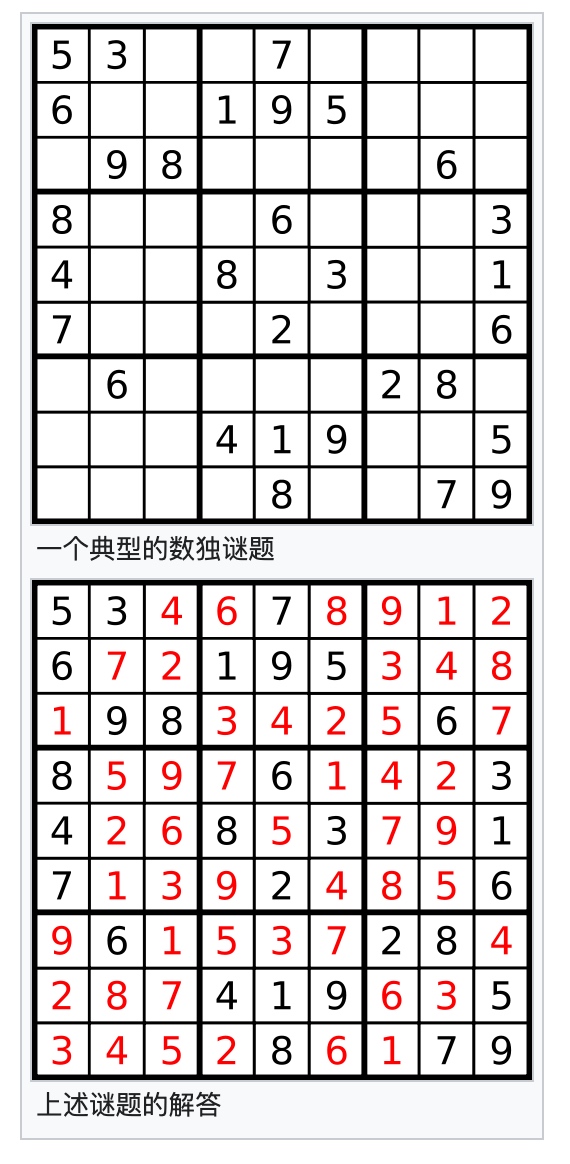
EMPTY = 0 defsodoku(board): defcan_put(board, row, col, c): for i in range(9): if board[i][col] != EMPTY and board[i][col] == c: # 行不冲突 returnFalse if board[row][i] != EMPTY and board[row][i] == c: # 列不冲突 returnFalse x, y = row // 3 * 3 + i // 3, col // 3 * 3 + i % 3 if board[x][y] != EMPTY and board[x][y] == c: # 九宫不冲突 returnFalse returnTrue
defsolve(board): for i in range(9): for j in range(9): if board[i][j] == EMPTY: for c in range(1, 10): if can_put(board, i, j, c): board[i][j] = c if solve(board): returnTrue else: board[i][j] = EMPTY returnFalse returnTrue return solve(board)
EMPTY = 0 defsodoku(board): defsolve(board): for i in range(9): for j in range(9): box_index = (i // 3 ) * 3 + j // 3 if board[i][j] == EMPTY: for c in (rows[i] & columns[j] & boxes[box_index]): # 通过集合来剪枝 # 设置状态 board[i][j] = c tmp = [False, False, False] for idx, elem in enumerate((rows[i], columns[j], boxes[box_index])): if c in elem: elem.remove(c) tmp[idx] = True # 进入下一层递归 if solve(board): returnTrue # 还原状态 board[i][j] = EMPTY for idx, elem in zip(tmp, (rows[i], columns[j], boxes[box_index])): if idx: elem.add(c) returnFalse returnTrue
# 验证题目是否合法, 初始化每一格可选择项 rows = [set(range(1,10)) for i in range(9)] # 行内所有点的可选值 columns = [set(range(1,10)) for i in range(9)] # 列 boxes = [set(range(1,10)) for i in range(9)] # 九宫 for i in range(9): for j in range(9): num = board[i][j] if num != EMPTY: num = int(num) box_index = (i // 3 ) * 3 + j // 3 if num notin rows[i]: returnFalse rows[i].remove(num) if num notin columns[j]: returnFalse columns[j].remove(num) if num notin boxes[box_index]: returnFalse boxes[box_index].remove(num) return solve(board)
deftop(self): if self.length > 0: return self._items[1]
defdel_top(self): if self.length > 0: self.exch(1, self.length) val = self._items.pop() self.sink(1) return val
def__repr__(self): tmp = [] seq = ' ' for i in range(1, self.depth+1): l = seq.join([str(e) for e in self._items[2**(i-1):2**i]]) tmp.append(l) return'\n'.join(tmp)
]]>
<p>英彦有云,魔鬼在细节之中(The devil is in the details),其意义在于提醒人们,不要忽视细节,即使是微不足道的小处也可以影响大局。</p>
<p>换个角度思考,这句话用在学习上,是再贴切不过了。当我们接触一个新领域时,其中的每个知识细节,都是魔鬼,稍有不慎就会被魔鬼击败,产生厌学情绪,再起不能。只有除尽这些魔鬼,才能攀上知识的高峰。<br>